Abstract
We introduce ViMU, a benchmark for Video Metaphorical Understanding. ViMU tests whether multimodal models can move beyond literal video description and infer implicit meaning, rhetorical devices, social signals, target subjects, and culturally grounded subtext. The benchmark contains 588 curated videos and 2,352 questions across open-ended and multiple-choice tasks. All questions are designed to be hint-free, so models must infer the intended meaning from multimodal evidence rather than from leaked answer cues. Experiments on 16 MLLMs show that current frontier models still struggle with video subtext understanding.
Benchmark
588
Curated videos
2,352
Questions
4
Evaluation tasks
16
Evaluated MLLMs
Design
ViMU separates literal video content from the intended meaning behind it, covering rhetoric mechanisms, social value signals, evidence sources, and target subjects.
Rhetoric mechanisms
Social value signals
Evidence sources
Target subjects
Tasks
Each task probes a different aspect of video subtext understanding.
OE
Explain the intended meaning of the video without answer hints.
EG
Select the multimodal cues that support the interpretation.
RM
Identify how the video constructs implicit meaning.
SV
Identify the social stance or value signal conveyed by the video.

Open-ended interpretation
Evidence grounding

Rhetoric mechanisms

Social value signals
Open-ended interpretation, evidence grounding, rhetoric classification, and social-value classification.
Results
Even strong models often describe the video correctly but miss its rhetorical or social meaning.
| Model | Date | OE | EG | RM | SV | SSU-Avg | All-Avg |
|---|---|---|---|---|---|---|---|
| Open-weight Models | |||||||
| Ministral-8B | 2024-10 | 48.25 | 48.60 | 31.87 | 10.45 | 21.16 | 34.79 |
| Ministral-14B | 2025-12 | 52.19 | 55.73 | 27.29 | 6.57 | 16.93 | 35.45 |
| Gemma-3-4B-it | 2025-03 | 39.43 | 25.41 | 21.10 | 7.17 | 14.13 | 23.28 |
| Gemma-3-27B-it | 2025-03 | 55.90 | 49.38 | 32.47 | 7.95 | 20.21 | 36.43 |
| Qwen3-VL-32B-Instruct | 2025-10 | 64.09 | 59.64 | 27.65 | 15.17 | 21.41 | 41.64 |
| Qwen3.5-27B | 2026-02 | 62.80 | 60.28 | 38.18 | 22.40 | 30.29 | 45.91 |
| Closed-source / API Models | |||||||
| Claude-3-Haiku | 2024-03 | 50.41 | 34.55 | 2.99 | 3.64 | 3.32 | 22.90 |
| GLM-4.5v | 2025-08 | 62.52 | 23.11 | 8.87 | 9.26 | 9.06 | 25.94 |
| Grok-4.1-Fast | 2025-09 | 57.62 | 63.84 | 34.91 | 28.73 | 31.82 | 46.28 |
| Gemini-3-Flash-Preview | 2025-12 | 62.54 | 52.80 | 33.63 | 28.26 | 30.94 | 44.31 |
| Mimo-V2-Omni | 2026-03 | 64.07 | 48.94 | 21.04 | 18.52 | 19.78 | 38.14 |
| Seed-2.0-Lite | 2026-03 | 60.84 | 66.16 | 18.75 | 16.73 | 17.74 | 40.62 |
| o4-mini | 2025-04 | 65.27 | 59.63 | 33.21 | 29.51 | 31.36 | 46.91 |
| GPT-4.1-nano | 2025-04 | 50.12 | 22.31 | 2.32 | 9.02 | 5.67 | 20.94 |
| GPT-5.2 | 2025-12 | 73.15 | 67.83 | 16.55 | 21.15 | 18.85 | 44.67 |
| GPT-5.4-mini | 2026-03 | 66.19 | 64.45 | 4.17 | 11.77 | 7.97 | 36.64 |
Main results on ViMU. OE: open-ended interpretation; EG: evidence grounding; RM: rhetoric mechanisms; SV: social value signals. SSU-Avg averages RM and SV; All-Avg averages all four tasks. Green cells mark top-3 scores, and purple cells mark bottom-3 scores.
Analysis
Finding 1
Models that perform well on open-ended description can still fail on rhetoric and social-signal classification.
Finding 2
Many grounding errors come from missing necessary evidence rather than over-selecting irrelevant cues.
Finding 3
They tend to prefer generic or safer categories and under-predict more implicit or socially coded meanings.
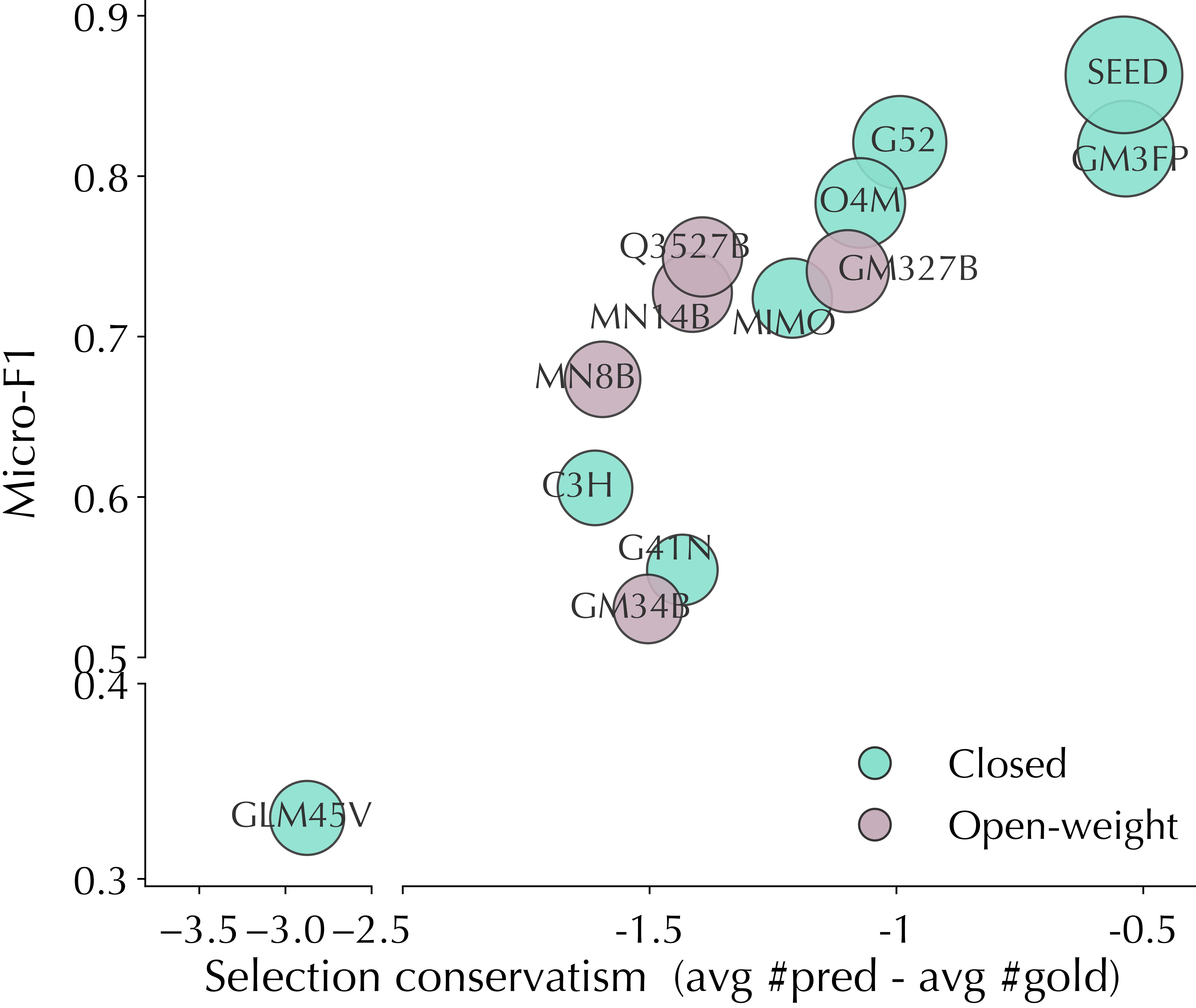
Conservatism vs. performance
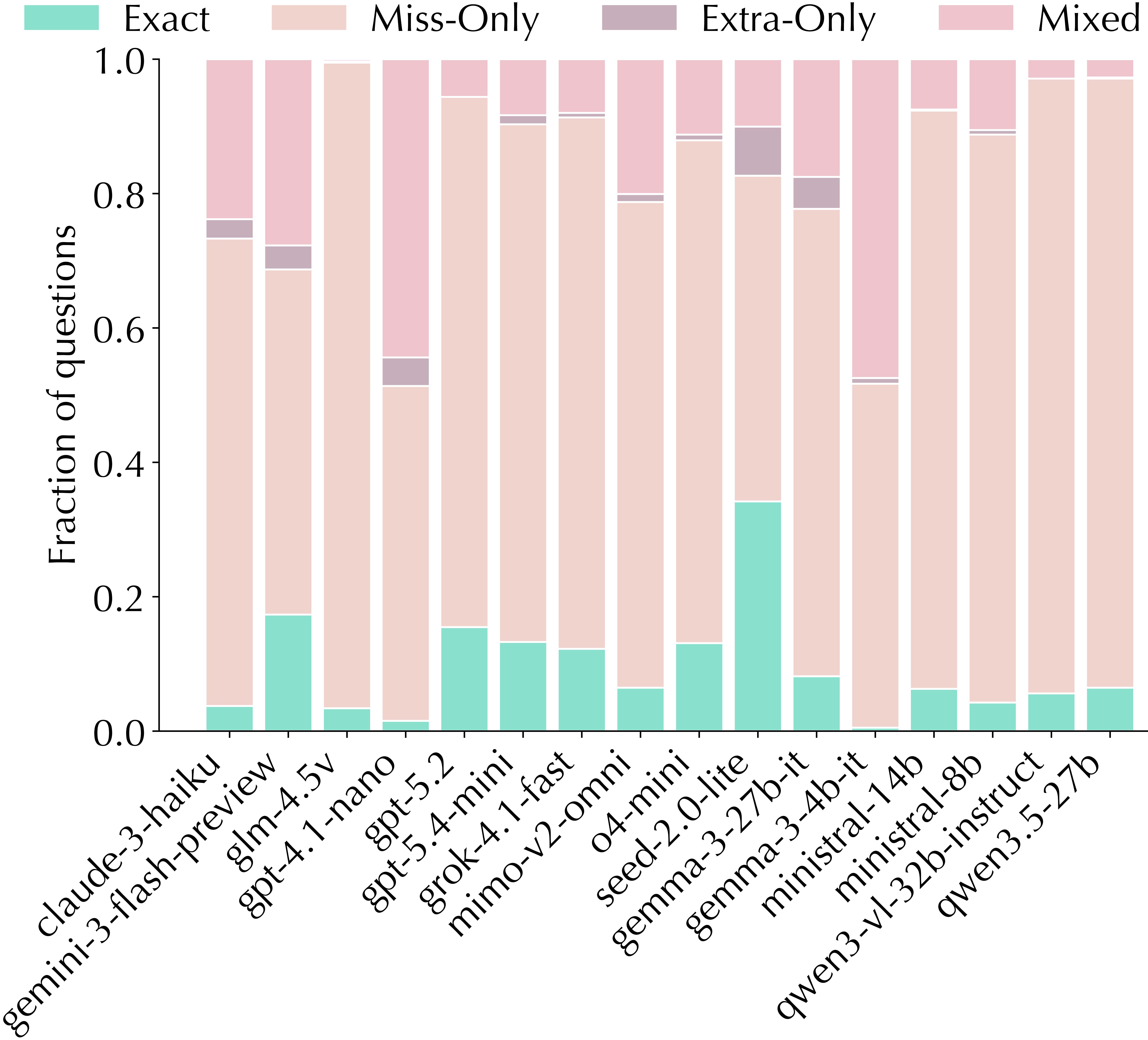
Error composition
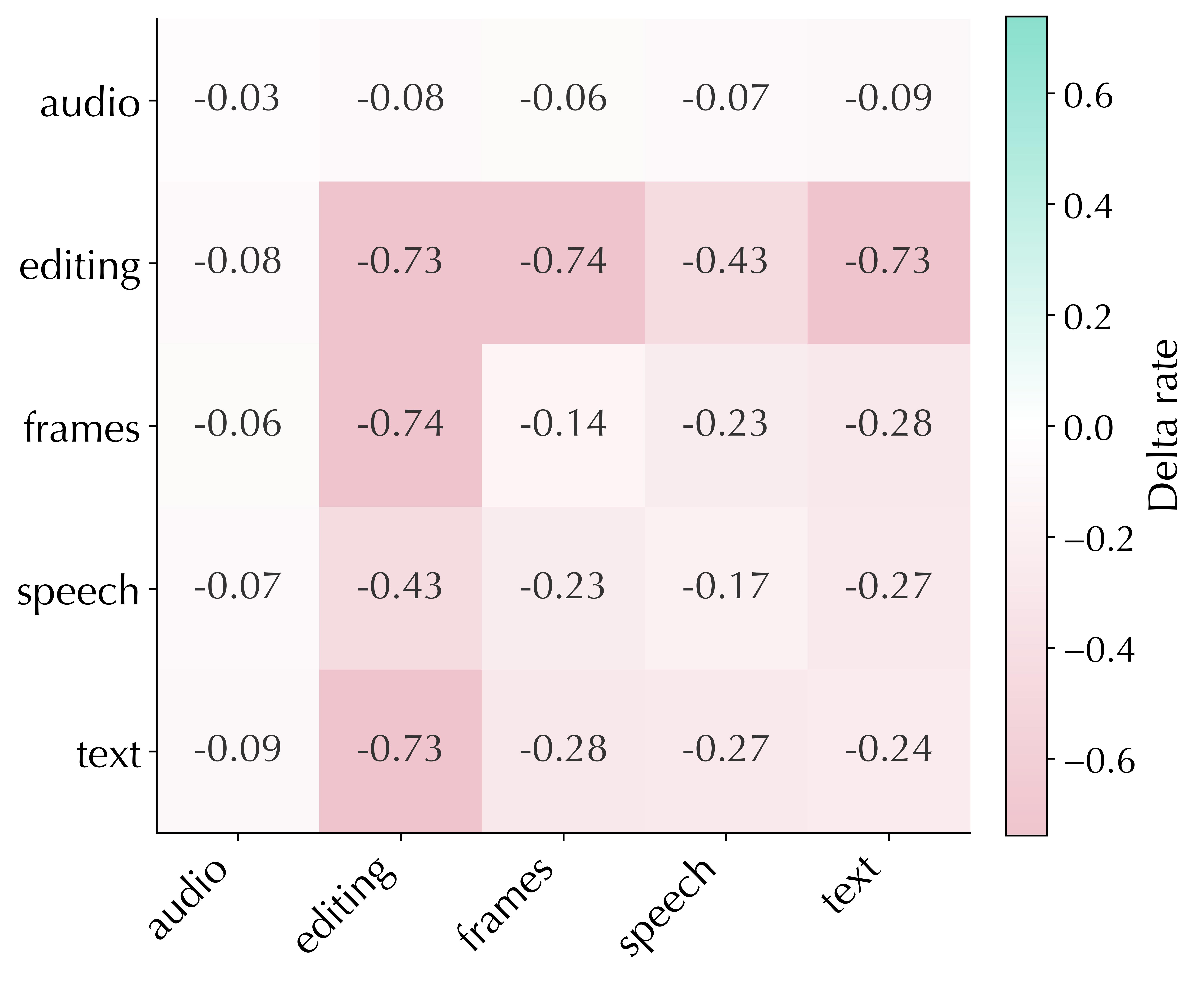
Relation distortion
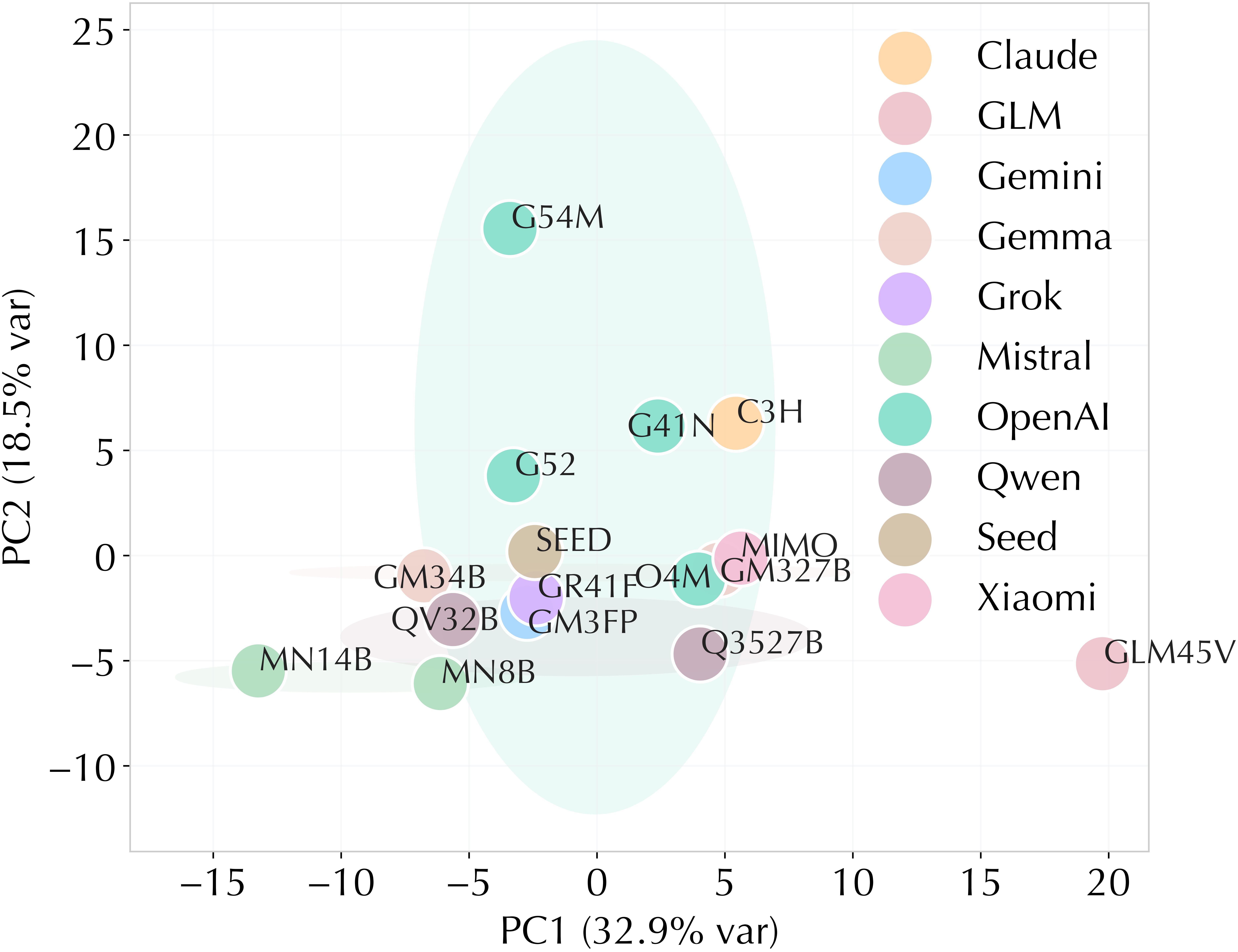
Model similarity
Evidence grounding behavior and model-level error similarity.

Rhetoric affinity
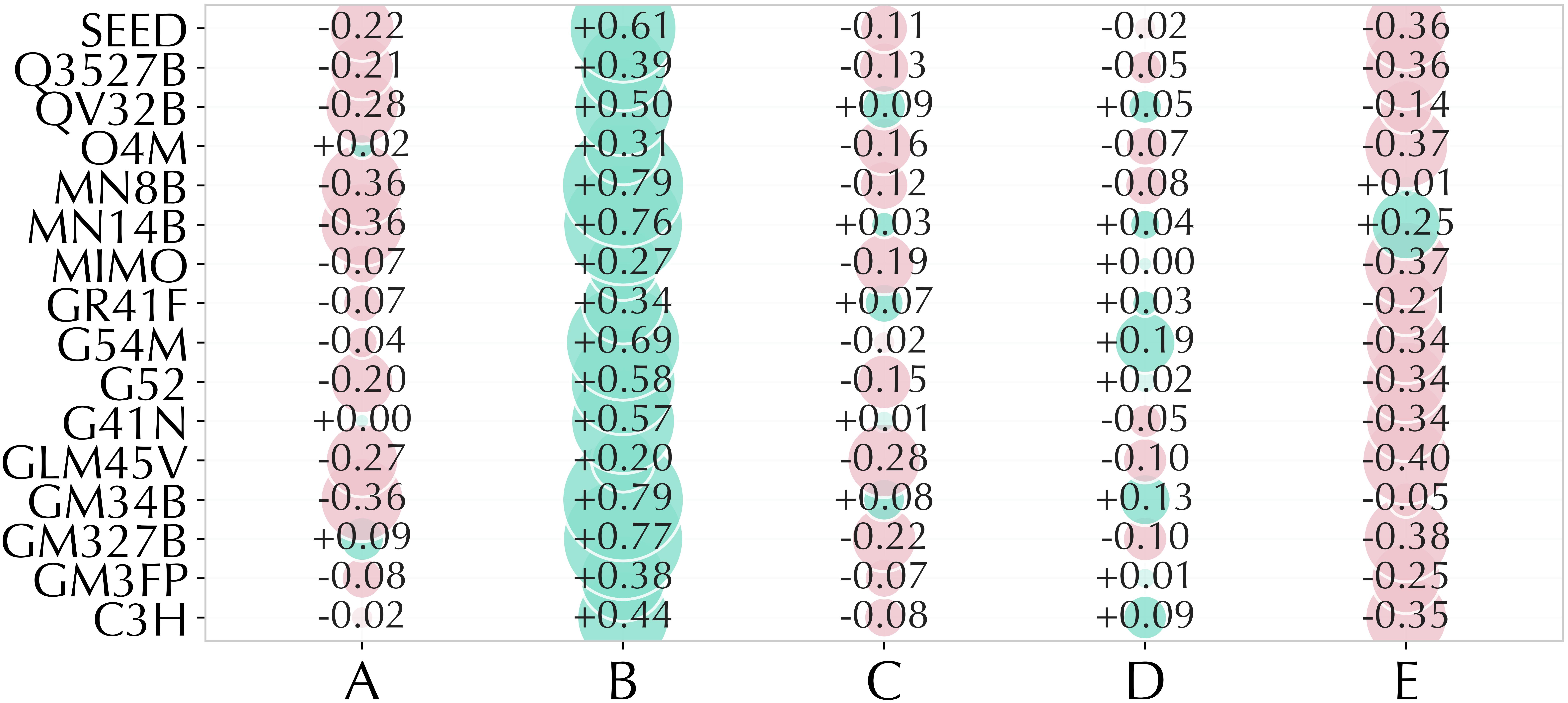
Social-value affinity
Taxonomy geometry
Option-affinity bias and taxonomy-geometry distortion.
@article{li2026vimu,
title={ViMU: Benchmarking Video Metaphorical Understanding},
author={Li, Qi and Wang, Xinchao},
journal={arXiv preprint arXiv:2605.14607},
year={2026}
}
